В наше время мы зависим от компьютеров и от надёжности хранения данных в компьютерах. В этой статье я постарался собрать наиболее сжато основные идеи и принципы, важные для сохранения данных. Эти соображения взяты из материалов, которые я готовлю для книги на эту тему. Мне бы хотелось знать, какие вопросы наиболее актуальны и интересны читателям, что ещё стоит осветить.
Содержание
От чего мы защищаемся?
Резервное копирование и/или архивирование
«Совместный рост»
Плюсы «совместного роста»
Минусы «совместного роста»
Резервное копирование (backup)
Отстающая копия
Проверка резервной копии и «подстригание лужайки»
Архивирование
Требования к архиву
Сколько нужно копий данных?
Устойчивость к катастрофам
Куда копировать? Носители (media)
Носитель или устройство?
HDD, SSD, Flash
NAS, RAID и другие
Облачные службы
Каталогизация. Как мы помним, что где?
Каталогизация. Тома и метки томов
Каталог работ
Конвертация архива и каталога
Выводы
От чего мы защищаемся?
Наши данные могут пострадать от следующих факторов:
- потеря или повреждение оборудования;
- сбой оборудования;
- ошибка (баг) в какой-то из программ;
- вредоносные программы: вирусы, ransomware;
- человеческая ошибка: мы сами можем что-то по ошибке стереть или перезаписать, или по ошибке сохранить изменения, которые не собирались сохранять.
Резервное копирование и/или архивирование
Эти понятия в чём-то схожи, и люди часто путают резервное копирование (backup) и архивирование.
Резервное копирование (backup) — это копирование данных на случай сбоя компьютера или диска, на котором хранятся данные. Тут важно быстро и надёжно вернуть пострадавшие данные в случае сбоя.
Архивирование — это долговременное хранение данных для того, чтобы вернуться к ним снова, спустя время. Тут главная цель — быть в состоянии найти и прочитать нужные данные, ведь данных может быть много, а методы работы, программы и аппаратура могут с тех пор измениться.
Это задачи схожие, и в чём-то пересекаются, но их специфика во многом отличаются.
Для резервного копирования главная цель — быстро вернуться в строй, восстановить повреждённые файлы, а главный фактор — время, которое нам для этого понадобится, в зависимости от риска сбоя. Это определяет усилия и вложения на резервное копирование. Например, электрической компании или системе платежей, в случае сбоя, необходимо вернуться в строй в считанные секунды, поэтому у них в резерве есть готовая к употреблению система, аналогичная основной. А для наших фотографий, в случае сбоя компьютера, мы можем себе позволить потратить на восстановление несколько часов. Мы взвешиваем риски. Если у нас будет время в случае сбоя починить компьютер или купить новый, а потом вернуть данные — это одна ситуация. А если нет такой возможности, или есть срочность — ну что ж, тогда необходимо подготовить запасной компьютер и держать его наготове, но это другие деньги и другие затраты времени, ведь этот запасной компьютер тоже надо поддерживать в готовом к работе состоянии, надо, чтоб на нём были все необходимые программы и настройки.
Чем меньше риск, тем больше допустимое время простоя. Чем выше риск, тем больше надо вложить усилий в резервную копию.
При архивировании цели другие. Главная из них — в первую очередь, возможность найти необходимый документ (файл), по заданным критериям в разумное время. Не менее важная цель — гарантия подлинности. Открывая файл, сохранённый в 2004-м году, я должен быть уверен, что это тот самый файл, в том самом виде, в каком был записан.
При архивировании появляются и дополнительные аспекты, связанные с размером и временем хранения:
Каталогизация — мы должны иметь представление, что мы храним, где, и как будем искать. В отличие от резервного копирования, нам вряд ли понадобится вернуть все данные на своё место. Скорее всего, нам из архива потребуется какой-то один или несколько документов. Или потребуется просмотреть архив за определённое время или по определённой теме, чтобы отобрать файлы (документы, фотографии) для какой-то цели. Поэтому мы должны иметь какую-то систему, методологию, чтобы найти нужный документ. Надо продумать ключи поиска: по годам, по темам, по людям;
Подлинность — нужно гарантировать, что архивный файл не менялся с тех пор, как был создан. Идеально было бы, чтобы он вообще был только для чтения, как CD или DVD;
Формат — надо учитывать, что программы, которыми мы пользуемся, когда архивируем, могут отличаться от тех, которыми будем пользоваться, когда будем читать этот архив.
Таблица: Архивирование и резервное копирование
| Резервное копирование | Архив |
|---|---|
| копия текущих данных, в современном формате, в расчёте на текущую версию программных средств | возможно, будет читаться будущими версиями или даже другими программами |
| объём данных не превышает размер диска текущего компьютера | общий объём данных может значительно превышать хранилище теперешнего компьютера |
| приоритет в скорости восстановления данных | приоритет в возможности найти нужные данные по разным критериям: по годам, по темам, по проектам, по тегам |
| структура данных повторяет структуру текущего компьютера | структура данных построена так, чтоб учитывать фактор времени и разнообразие критериев поиска: по времени, по теме; в структуре данных может быть отражено, с какого компьютера сохранены данные, когда |
| обычно не каталогизируется | требует каталогизации: что записано, где, и когда |
| файлы операционной системы, настройки, программы, могут быть сохранены вместе с данными, для быстрого ввода в строй | сохраняется только содержимое (content) – документы, имеющие историческую ценность: то, с чем мы будем работать, то, что мы хотим найти в будущем |
| копия изменяется вместе с текущими данными, всегда соответствует текущему состоянию оригинала | архив (в основном) не изменяется, только дополняется |
| обычно нужна одна-две копии (при наличии действующего архива) | нужны минимум три копии*** |
| должно выполняться автоматически | чаще всего, требует ручного участия: нужно определить, что именно будет архивироваться, создать структуру данных пригодную для архивации и поиска в будущем, и должным образом каталогизировать*** |
*** будет подробно рассмотрено ниже
«Совместный рост»
У многих людей весь их архив целиком умещается на диске одного компьютера. Возможно, даже у большинства. Это иногда позволяет в какой-то мере объединить решение обеих задач: резервного копирования и архивирования.
Тогда весь диск компьютера, со всем полным архивом, просто копируется на другое устройство или в облако (о количестве копий и об облаках будет подробнее рассказано дальше). Можно воспользоваться программой перенесения изменений, или «синхронизации», например, SyncToy или BeyondCompare, и просто переносить новые и изменившиеся файлы в резервную копию.
Я назвал эту методологию «совместным ростом», потому что предполагается, что технологии развиваются вместе с ростом нашего архива, и до того момента, как архив достигнет пределов нашего носителя, или компьютера, на рынке появится диск или компьютер большего объёма, который снова сможет уместить весь наш архив. До сих пор это условие соблюдалось: мощности компьютеров и предоставляемые объёмы в течение последних 20-25 лет росли так, что обычно, можно предположить, обгоняли рост архивов большинства пользователей.
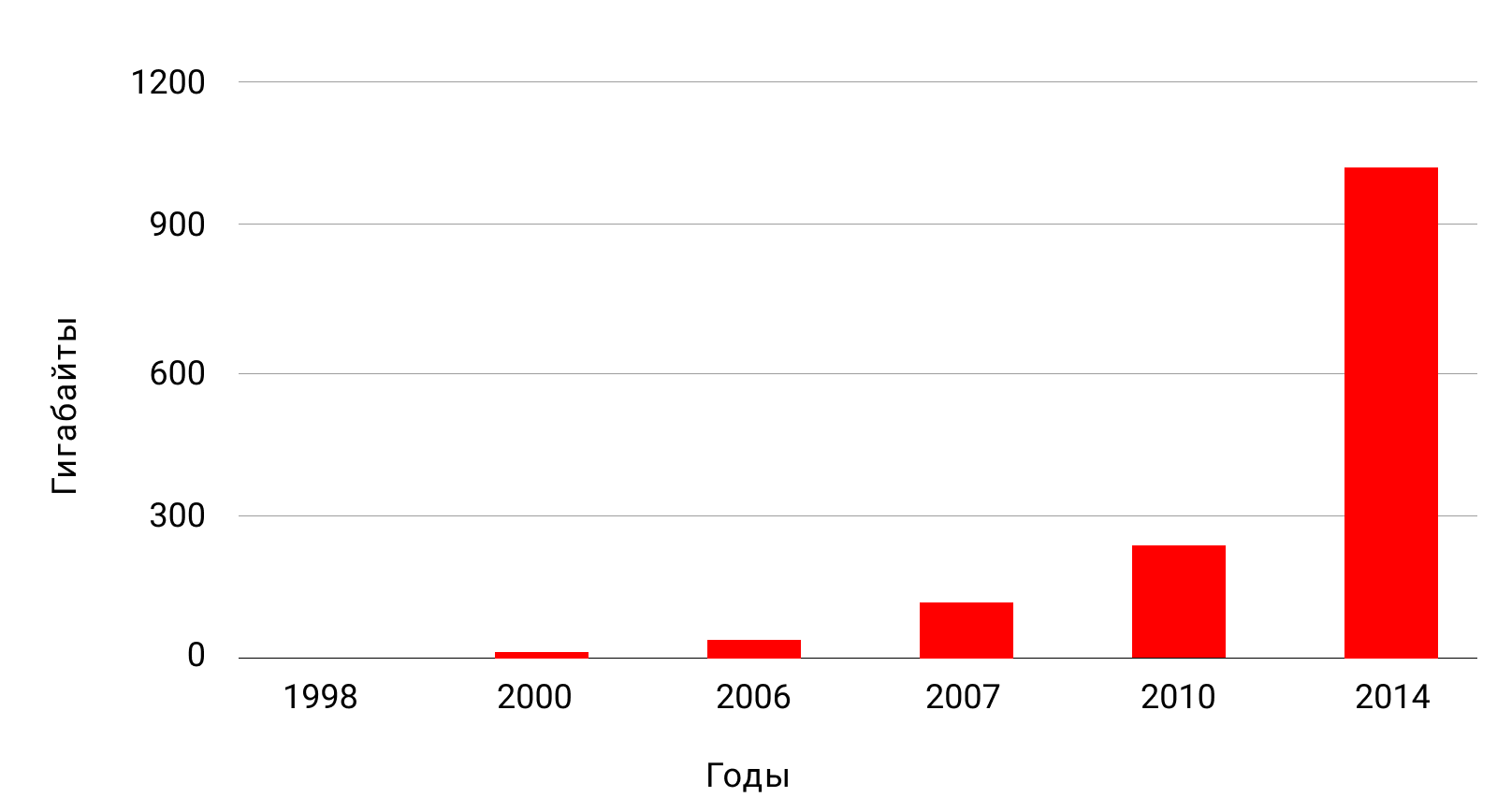
Таблица: рост мощностей "типичного" компьютера, на примере моего компьютера в разные годы
| Процессор, тактовая частота | Память (ОЗУ) | Диск | |
|---|---|---|---|
| 1994 | 33 МГц | 4 МБ | 80 МБ |
| 1996 | 100 МГц | 12 МБ | 850 МБ |
| 1998 | 266 МГц | 80 МБ | 2 ГБ |
| 2000 | 400 МГц | 256 МБ | 10 ГБ |
| 2006 | 1.6 ГГц | 512 МБ | 40 ГБ |
| 2007 | 1.6 ГГц | 2 ГБ | 120 ГБ |
| 2010 | 1.6 ГГц | 4 ГБ | 240 ГБ |
| 2014 | 2х2.7 ГГц | 16 ГБ | 1 ТБ |
| 2020 | 4х2.7 ГГц | 32 ГБ | 2х1 ТБ |
Объём диска в моём компьютере в разные годы
Плюсы «совместного роста»:
- архив не разделён на части и тома, нет необходимости в каталоге, на каком носителе (в какой части, на каком томе) находится определённый файл, проект или период;
- архив может быть просканирован различными программами каталогизации, например, Adobe Lightroom, в один приём; не надо подключать и отключать внешние носители;
- можно произвести поиск сразу по всему архиву;
Минусы «совместного роста»:
- архив со всей информацией всегда «в работе», может пострадать целиком от сбоя оборудования или вредоносной программы, или человеческой ошибки;
- когда кончится место на диске, нужно будет добавить диск в компьютер (если файловая система позволяет «расшириться» на новое физическое устройство) или поставить новый, больший диск и скопировать на него все данные, включая операционную систему; это может быть дороже и труднее, чем просто добавить новый диск к имеющимся;
- совместный рост не решает задачу «отключённого» носителя. О необходимости «отключённого» носителя мы говорим в разделе «требования к архиву».
Схема: Методологии «совместного роста» и архивирования


«Совместный рост» подходит не всем, иногда это вопрос осознанного принятия решения.
Возьмём, например, меня. В каждый конкретный год мой архив, наверное, мог уместиться на достаточно мощный современный стационарный компьютер. Но мне нужен был именно портативный компьютер, для возможности работы с фотографиями в поездках, а у лэптопов возможности хранения и расширения всегда более ограничены, чем у современных им стационарных компьютеров.
В 2006 году мой архив был примерно 300ГБ. Стационарный компьютер с двумя дисками по 200ГБ мог бы его уместить, но у меня был лэптоп с диском в 40ГБ, а затем 80ГБ.
Сейчас мой архив 21ТБ. На рынке есть диски 12, 14 и 16ТБ. Стационарный компьютер с дисками 12 и 14ГБ мог бы его уместить, но сейчас у меня лэптоп с двумя накопителями SSD по 1 терабайту каждый.
В конечном счёте всё просчитывается с точки зрения оправданности вложений. Можно построить монстроидальную систему, в которой все данные будут доступны одновременно, но всегда ли все данные нужны сразу? Иногда выгоднее хранить данные отдельно, упрощается конфигурация, оборудование дешевле.
Резервное копирование (backup)
Главное требование к резервному копированию — чтобы оно было. Сейчас, к сожалению, люди иногда даже не задумываются, что компьютер может испортиться, но это может случиться, и чем больше возраст компьютера, тем вероятнее сбой. У дисков вообще ограниченный срок жизни, после определённого количества циклов записи-чтения надёжное хранение данных не гарантируется. Иными словами, рано или поздно информация на компьютере (планшете, телефоне) обязательно испортится. Не говоря уже о возможности потерять или уронить компьютер. Особенно — мобильный. Особенно — мобильный телефон.
Лучше всего, чтобы резервное копирование выполнялось автоматически, это может быть специальная, отдельно купленная программа, или встроенные средства операционной системы, или программа, поставляющаяся с внешним жёстким диском, или клиент от «облачной» службы. Мы хотим, чтобы наши данные регулярно копировались «в сторону», на резервное устройство, и чтобы изменения «синхронизировались».
Резервная копия может либо «синхронизироваться», когда все изменения, в том числе и удаления, переносятся на копию, либо «накапливаться», когда переносятся все изменения и добавления, но не удаления. Последний вариант спасает от человеческой ошибки, случайного удаления файла.
Резервная копия может выполняться
- на другой носитель в том же компьютере;
- на внешний носитель;
- на другой компьютер в локальной сети (это может быть домашний сервер, или «подключённое по сети хранилище» (NAS) (о NAS мы будем говорить дальше);
- в интернет (в «облако»).
Можно настроить резервное копирование так, чтобы файлы копировались сразу же по мере изменений. Это нужно, обычно, только если мы работаем с нескольких устройств одновременно, и тогда предпочтительно, чтобы копия была в локальной сети или в «облаке», то есть, чтобы она была доступна сразу со всех устройств. Если же мы работаем с одним компьютером, а копия нам нужна только на случай его сбоя, то нет необходимости сразу же копировать все изменения, вполне достаточно копирования раз в день, и его можно запланировать на ночь. Тогда, в случае сбоя, в худшем случае, мы потеряем изменения за день. Если эти изменения очень важны, и мы потратили много сил на них, можно запустить резервное копирование вручную сразу после этих изменений.
В принципе, очень желательно иметь более одной резервной копии, потому что копия также может быть подвержена сбою или поломке. Разумно сделать разные резервные копии разными технологиями: например, внешний диск и сервер в локальной сети; или локальная сеть и облако.
Та же методология и дисциплина должна быть при скачивании фотографий с карточек и из фотоаппаратов. Копируем сразу в два места: основное и резервное, это должны быть два разных носителя, или один носитель и «облако». В случае сбоя компьютера или диска мы не хотим потерять весь съёмочный день. Во всех программах выкачивания из фотоаппаратов, которые я видел, предусматривается возможность копировать сразу в два места, основное и резервное.
Отстающая копия
Раз уж мы делаем две резервные копии данных с главного компьютера, то иногда помогает делать эти копии в два места с разной частотой, например, в локальной сети — каждый день, а на внешний накопитель — раз в неделю.
Или, например, «быстрая» копия на сервер в локальной сети, а «медленная» — в облако, реже и медленнее, по мере возможностей «исходящего» трафика (upload) вашего подсоединения к интернету.
«Отстающая» копия защищает не только от случайного удаления, но и от случайной модификации файла. Бывало, что я по ошибке сохранял изменения, которые не планировал сохранять. Или это была проба, или я уменьшил файл для интернета, и по ошибке сохранил в основной файл, а не в другой. Вчерашняя копия может быть спасением.
Некоторые файловые системы и облачные службы поддерживают «версии», то есть фактически сохраняют несколько копий каждого файла: актуальное состояние, предыдущее состояние (перед последним изменением), пред-предыдущее состояние, и т. д. Это тоже может спасти от ошибочных изменений, надо только хорошо себе представлять, сколько версий каждого файла хранится, управлять объёмами.
Можно сделать так, чтобы одна из резервных копий, наиболее легко доступная, была «синхронизированной», то есть включала удаления, а другая, «медленная», и более редкая, «отстающая» копия, была «накапливающей», то есть без удалений. Тогда при случайном удалении или перезаписи файла его можно будет вернуть с «отстающей» копии.
Проверка резервной копии и «подстригание лужайки»
Периодическое сравнение текущего компьютера с резервной копией позволяет обнаружить, что изменилось, и задуматься, это «легитимное» изменение или какая-то ошибка. Сравнивать текущее состояние с резервной копией можно с помощью уже упомянутого BeyondCompare, WinDiff или им подобных.
Понятно, что «накапливающая» копия (в которую не переносятся удаления), без вмешательства вручную, будет только расти. При сравнении с оригиналом мы увидим в копии файлы, которые в оригинале были удалены. Мы также можем увидеть файлы, которые были переименованы, потому что переименованный файл уже добавлен в резервную копию, а файл со старым именем был там раньше, и тоже остался. Когда мы удостоверились, что нужный файл уже есть на копии, лишний файл со старым именем можно стереть. Это напоминает подстригание травы на лужайке.
После архивирования, когда мы убрали какие-то готовые, законченные файлы в архив (об этом подробно ниже), и они ушли с нашего рабочего диска, мы их, опять же, увидим оставшимися в резервной копии рабочего диска, и тоже «подстрижём».
Мы вырабатываем такую систему, которая, с одной стороны, будет как можно более автоматическая, не будет требовать каждодневного внимания и серьёзных усилий «вручную» на её поддержание. С другой стороны, она должна давать нам возможность понять, что изменилось, где ошибка. Мы ищем баланс между затратами сил, времени и денег, с одной стороны, и рисками с другой стороны.
Пример
- Моя главная папка с документами, «мои документы» («my documents» в windows), автоматически синхронизируется с Google Drive. Google Drive предоставляет до 15ГБ бесплатно, этого более, чем достаточно для «текущих» документов. Если компьютер сломается, то с другого компьютера легко подсоединиться к Google Drive, и все документы будут на месте. Вторая, «медленная», копия делается каждую ночь на сервер в локальной сети.
- С фотографиями система иная, поскольку совершенно другие объёмы данных, но и другая частота изменений. Первая, «быстрая», копия делается на сервер в локальной сети, а вторая, «медленная» — в Amazon Drive. Пользователи Amazon Prime могут хранить неограниченный объём фотографий. Поэтому я туда загружаю вторую копию всех своих фотографий с главного компьютера. Понятно, что фотографии загружаются в облако достаточно медленно, но ведь и сбой одновременно и компьютера, и локального сервера не так вероятен.
Мы поговорили о методиках и критериях резервного копирования (backup), а теперь обратимся к вопросам долговременного хранения, то есть архивации данных.
Архивирование
Архивирование — задача в чём-то схожая с резервным копированием, но и другая. При резервном копировании мы копируем все данные, с которыми часто работаем («основные»), а при архивировании мы «убираем» в архив те данные, которые уже, скорее всего, не будут меняться, но убираем их так, чтобы могли их легко найти и прочитать.
Идея, в общем, в том, что мы не можем или не хотим хранить «под рукой», на одном компьютере, абсолютно все данные. Какие-то данные нам больше не нужны, и мы их просто удаляем, а с другими мы «закончили работать», они нам больше не понадобятся «прямо сейчас», но могут понадобиться в будущем. Мы не хотим держать их всё время «под рукой», потому что иначе наш «рабочий диск» сильно увеличится, и все его резервные копии вместе с ним. Данные, которые нужны не всё время, а могут понадобиться в будущем, мы переносим в архив.
Архив не предполагает изменений. Если мы создали документ в 2008-м году, а в 2014-м решили его изменить, то мы не будем обновлять архив 2008-го года, мы занесём новую копию документа в архив 2014-го, и сделаем так, чтобы было понятно, что этот документ создан в 2008-м и модифицирован в 2014-м.
Архив, в общем, не предполагает удалений. В бизнесе есть понятие «политики устаревания» (retention policy) и там решается, через сколько времени можно уничтожить, например, старую переписку, старую бухгалтерию, и т. п. В реальной частной жизни мы этими вопросами (почти) не занимаемся. В каких-то случаях удаление возможно, в других — не стоит усилий. Например, понятно, что можно уничтожить старые счета за электричество. Но для этого они должны быть в отдельной папке, в которой маркирован год, и в которой только счета. Тогда, например, если у меня есть папка «2011.коммунальные услуги», то, например, в 2020-м году я могу эту папку стереть. Но, в принципе, при теперешних ценах и технических возможностях, я могу вообще не архивировать счета за коммунальные услуги, а просто подержать их лишний год-два в «рабочем наборе». Как уже говорилось, в Google Drive у меня есть 15ГБ бесплатно, этого с лихвой хватает на несколько лет «текущих» документов. А вот, например, с фотографиями — другая политика. Исходные файлы, выкачанные из камеры, просмотрены, нерезкие и недостойные удалены, а из каких-то сделаны работы. Понятно, что после этого и исходные файлы, и работы со временем пойдут в архив, и там уже удаление не предполагается. Зато предполагается разумное количество усилий по маркировке данных, так, чтоб их можно было при надобности легко найти. Об этом и речь далее.
Требования к архиву
Архив не должен пострадать ни от сбоя оборудования, ни от человеческой ошибки. Поэтому логично требовать от архивного носителя, чтобы он был физически отключён от компьютера и, конечно же, от интернета. С другой стороны, наши меры защиты не должны быть такими строгими, как, например, у военных, или в системах безопасности атомных электростанций. Понятно, что нет смысла отсоединяться от интернета и спускаться в бункер, чтобы работать со своими фотографиями. Мы предполагаем, что на нашем компьютере установлен нормальный антивирус, а подключение к интернету защищено нормальным домашним файрволлом. Но поскольку сбои, атаки и вирусы всё-таки реально случаются, мы хотим, чтобы кроме той копии архива, которая сейчас подключена к компьютеру, остальные были физически отключены. Это и есть базовое правило: работаем всегда с одной копией, и у нас всегда должны быть ещё копии данных, физически отключённые от компьютера. Желательно, чтоб эти копии вообще были без возможности модификации, как когда-то DVD. Тогда, открывая файл, мы уверены, что это тот самый файл, который был записан при архивации. Сейчас мы не пользуемся DVD, пользуемся внешними накопителями, которые могут пострадать от вирусов, и у них может быть модифицирована или испорчена система путей и папок и целые регионы, записанные ранее, могут оказаться недоступными. Вредоносные программы могут зашифровать данные и потребовать выкуп за расшифровку, это называется «ransomware». Мы не хотим ни платить большие деньги за восстановление данных с испорченных дисков, ни тем более платить преступникам за расшифровку. Если испортится диск, если вредоносная программа испортит или зашифрует данные, мы просто покупаем новый диск, или полностью форматируем испорченный или «зашифрованный» диск, и возвращаем данные с других копий архива. И поэтому возникает следующий вопрос:
Сколько нужно копий данных?
Короткий ответ — минимум три. Логика такова: первая копия — собственно данные, вторая — на случай потери или порчи первой, третья — на случай сбоя компьютера во время копирования первой на вторую или второй на третью, ведь во время такого копирования могут испортиться сразу обе. У меня случались ситуации, когда из-за сбоя в драйвере USB во время копирования одного диска на другой, оба диска оказались нечитаемыми, причём не только те файлы, которые копировались, а и многие другие. Третья копия — жизненная необходимость. Без шуток и паранойи.
В отличие от резервных копий (бэкапов), где мы делали одну-две копии с разной частотой и разными технологиями (да ещё и одна из копий могла быть «отстающей»), в случае архива мы хотим три абсолютно идентичные копии, где идентичность легко проверить программой сверки, такой как BeyondCompare.
Каждая копия архива после записи требует верификации: физического прочтения и сравнения с оригиналом. Сократить этот путь можно таким образом: копируем оригинал в архив, копируем первую копию архива во вторую, копируем вторую копию в третью, третью сверяем с оригиналом бинарно, с помощью того же BeyondCompare, WinDiff или им подобных. Если третья копия совпала с оригиналом, значит, первая и вторая тоже совпадают, ведь они сделаны одна из другой. Тогда, и только тогда, оригинал можно удалить с «главного», «рабочего» диска. Это чем-то похоже на то, как мы «подстригали лужайку», когда сравнивали рабочий диск с его резервной копией — в окне программы сравнения. Как дополнительный бонус, WinDiff позволяет сохранить список сравнённых файлов, этот список станет основой каталога архива.
Конечно же, мы никогда не подключаем к компьютеру больше двух копий сразу. Обычно работаем с одной копией, а две подключаем, только когда копируем одну на другую. Но когда копируем вторую копию на третью, отключаем первую. В любой момент времени должна быть хотя бы одна копия архива, отключённая от компьютера и интернета.
Это не паранойя. Буквально на прошлой неделе фирма Apple сообщила об уязвимости, затрагивающей все операционные системы для «маков» и айфонов. Сам факт публикации починки производителем даёт понять взломщикам, в чём была проблема, и они могут атаковать устройства, которые ещё не успели установить обновление с починкой. Это называется «атака нулевого дня» (Zero-Day). А атака «с нулём кликов» (Zero-Click) означает, что злоумышленник мог воспользоваться уязвимостью, даже если пользователь не кликал ни на какие линки и не совершал никаких оплошностей. Объявленная уязвимость как раз и была Zero-day, Zero-click — фактически это означает, что в наш компьютер могли залезть из интернета без нашего ведома, и сделать там, что угодно. Это не фантастика, это происходит в реальной жизни. Опять же, я не призываю спускаться в бункер, носить бронежилет и противогаз. Просто отключите архивный диск от компьютера.
Эти простые меры могут избавить от многих, многих проблем, о которых я (слишком!) часто читаю в Фейсбуке у друзей: «скачок напряжения, сгорел компьютер, потерял(а) данные за последние полгода», «диск сломался и потерялись фотографии за пять лет».
Поймите меня правильно: то, что диск проработал пять лет — это просто замечательно. И это нас разбаловало, мы перестали ожидать, что он сломается. Но всё-таки его срок жизни ограничен, и он в постоянной работе, и в нём есть электроника и точная механика. Он обязательно сломается, износ неизбежен. Создание архивной копии — необходимость. Мой личный опыт начинается с 1980х, когда компьютеры были совсем не такими надёжными, и что-то в них ломалось едва ли не каждую неделю. Теперь наша техника прекрасна и надёжна, она предоставляет нам возможность заняться архивированием не прямо сейчас, а отложить это на недели или даже на месяцы, но нельзя забыть об этом совсем или отложить на годы. Компьютер сломается.
Устойчивость к катастрофам
Термин «восстановление от катастроф» (Disaster Recovery), опять же, приходит к нам из мира бизнеса и корпоративных вычислительных центров. «Катастрофа», в данном случае, это событие, затрагивающее весь филиал сразу, например, пожар, наводнение или землетрясение. Чтобы избежать потери данных, делаются копии географически в другом месте.
Пожалуйста, не надо думать про «катастрофу» как про что-то невероятное, которое ни в коем случае не может случиться. Совсем не обязательно нашествие марсиан или пожар в доме. Достаточно того, что диск, стоявший на столе, упадёт на пол. Или обрушится полка в шкафу. Или уронят тумбочку при переезде. Бутылка кока-колы, пролитая на фотоальбом — достаточно хороший пример? Может папка с дисками DVD случайно выскользнуть из рук и упасть на пол? Два поломавшихся диска — это 200 фотографий.
Хватит примеров катастроф. Я хочу сказать, что неразумно хранить все копии архива в одном месте. Ещё в 1999 году одну копию архива я держал дома, другую — в офисе на работе, а третью — у родителей. Это несложно, и они не занимают много места. Родственники и друзья охотно подержат у себя небольшой диск, его также можно легко послать по почте другу в другую страну. Но в наше время и этого делать не надо: роль географически удалённой копии прекрасно сыграют облачные службы. Поэтому дополняем формулу, выведенную выше: не просто три идентичные копии архива, а три идентичные копии архива, и хотя бы одна — в облаке или в другом месте.
И, кстати, о реальных катастрофах. Конкретно сейчас бушуют пожары в Калифорнии. На прошлой неделе ураган Ида затопил сотни домов в Нью-Йорке и Нью-Джерси. Из-за за той же Иды было эвакуировано население в Луизиане. В 2017 году наводнение повредило — до необходимости сноса — очень много очень дорогих зданий в Хьюстоне, и пострадал архив центра искусств в Галвестоне. Этим летом были пожары в Иерусалиме, а прошлой зимой — наводнения в Тель-Авиве и Ашкелоне, с затапливанием жилых домов и человеческими жертвами. За прошедшие пару лет я несколько раз слышал интервью с людьми, эвакуированными из своих домов, и потерявших в пожарах и наводнениях имущество. Особенно они сожалели о фотографиях, воспоминаниях, записях, дневниках. Так пусть хоть воспоминания будут сохранены. Мебель-то можно будет купить заново, получив страховку, а фотографии и документы страховка вам не вернёт.
Короче, «три копии плюс облако».
Куда копировать? Носители (media)
Рассмотрим кратко типы носителей, на которые мы копируем информацию. Сейчас практически нет большого разнообразия: мы храним данные либо на внешних жёстких дисках (Hard Disk Drive, HDD), либо на электронных полупроводниковых устройствах, «флэшках» (Solid State Drive, SSD или Flash Drive). Раньше были разные виды магнитооптических дисков: CDR, DVDR, BlueRay. Но мне хочется упомянуть о типах устройств, потому что этот вопрос может встать с нестандартными типами устройств на рынке.
Носитель или устройство?
Нужно понимать, что в случае дискет, оптических и магнитооптических дисков, магнитных лент и некоторых видов фотоаппаратных карточек, наш носитель (диск) хранит данные, а в компьютере должно быть устройство для их чтения. А в случае с внешним накопителем HDD или SSD — устройство для чтения находится в самом аппарате, и поэтому мы его можем подключить к любому компьютеру. Опять же, конкретно сейчас, в эти годы, это не так важно, потому что все имеющиеся сегодня на рынке устройства требуют от компьютера только порта USB. Но, в общем случае, это тоже критерий, который необходимо учитывать, если в будущем появятся какие-нибудь новые форматы архивных устройств или дисков.
Если мы имеем дело с носителем (дискета, оптический диск, лента), то нам понадобится устройство для его прочтения. Например, ленты DAT были удобны в пользовании и хранили больше информации, чем диски в то время: на кассету можно записать 4 или даже 24ГБ, в то время как на диск CDR — только 700 мегабайт. Лент нужно было гораздо меньше (в 30 раз!), и на ленту можно дозаписывать по мере надобности, её не надо, как диск, записать всю в один приём. И записанный кусок ленты не может быть испорчен следующей записью. Но устройство для чтения лент есть не у всех, оно само по себе может сломаться. И оно подключается к компьютеру через интерфейс SCSI, которого в новом или резервном компьютере может не быть, а если надо купить интерфейс SCSI, то он должен подходить к разъёму компьютера, и его драйвер должен быть совместим с той версией операционной системы, где данные придётся читать. Поэтому для архива я в те годы, в конце концов, сделал выбор в пользу дисков CDR, потому что они, хоть и требуют устройство для прочтения, но, по крайней мере, такое устройство было во всех обычных компьютерах, не было чем-то настолько экзотическим, как лентовод DAT.
Я так подробно останавливаюсь на этом примере из прошлого, потому что такой выбор может снова встать перед нами. Передовое, компактное, но экзотическое устройство, требующее специальной аппаратуры для работы с ним, или более «отсталый», зато очень распространённый носитель, который можно будет прочитать где угодно? Выбор будет зависеть от стоимости и эффективности того и другого, а также и от распространённости, и перспективы устаревания.
Предположим, например, что ленты вернутся и будут ужасно выгодны, например, появится новый тип кассеты, на которую можно будет быстро записать 20 терабайт, и лентовод будет подключаться к компьютеру по обыкновенному USB3.2. Для резервной копии это прекрасно! А для архива? Кинусь ли я переписывать все свои архивные диски на эти новые ленты? Допустим даже, что лентоводы и кассеты будут продаваться во всех магазинах, как когда-то зип-драйвы. Я могу купить в магазине такой лентовод, даже два (для надёжности), и постепенно перенести на него архив. Пройдёт 5, 10 лет, появится что-то новое, лентоводы начнут устаревать и потихонечку исчезать из продажи, а у меня уже записано много информации на эти ленты. Что мне тогда делать? Покупать «в запас» устаревающее устройство? Или переносить архив на что-то новое?
К сожалению, невозможно сказать заранее, сколько времени какая-то технология пробудет с нами.
В любом случае, надо хорошо представлять, что любой носитель когда-то устареет, и архив надо будет переносить на что-то новое, о чём я буду говорить дальше.
HDD, SSD, Flash
Вернёмся в сегодняшний день. Сегодня для хранения данных мы можем приобрести либо внешний жёсткий диск (Hard Disk Drive, HDD), либо внешний полупроводниковый «диск» (Solid State Drive, SSD, известный также как Flash Drive, или просто Flash).
Жёсткий диск — это механическое устройство с вертящимся внутри металлическим намагниченным диском. Соответственно, он более хрупкий, «боится» падений, толчков, не терпит никаких сдвигов во время работы, должен устойчиво стоять на твёрдой поверхности. Скачок записывающей головки от сдвига устройства может повредить данные, а в худшем случае — головка может поцарапать диск, а тогда и данные потеряются, и само устройство выйдет из строя. Однако, несомненный плюс этого устройства в том, что, при отсутствии механических воздействий, диск может сохранять информацию десятки лет, а информацию можно перезаписывать (почти) неограниченное количество раз. На сегодняшний день, по цене за терабайт данных, жёсткие диски дешевле полупроводниковых. Сегодня на Амазоне цена четырёхтерабайтного жёсткого носителя в 7 раз меньше, чем цена четырёхтерабайтного полупроводникового носителя.
Полупроводниковый «диск» SSD хранит данные с помощью хитрых микросхем. Мы их часто по инерции продолжаем называть «дисками», хотя, конечно же, в нём нет ничего ни круглого, ни вертящегося. Flash (или Flash Drive) и SSD — это практически одно и то же. Традиционно «флэшками» мы называем компактные устройства малого объёма, которыми пользуемся для переноса данных (8ГБ, 32ГБ, 128ГБ), а SSD обычно говорится про устройства, приходящие на смену жёсткому диску компьютера, т. е. 512ГБ и больше, хотя, в принципе, это практически одна и та же технология, и почти те же размеры.
Такой носитель намного быстрее, легче, в нём практически нет движущихся деталей, и поэтому он намного надёжнее, чем жёсткий диск. Единственная его проблема — ограниченное количество циклов перезаписи. Каждая ячейка памяти может быть в нём перезаписана несколько тысяч раз, я намеренно не упоминаю конкретные цифры, потому что эти показатели день ото дня улучшаются. С одной стороны, для архивного диска, кажется, что это не проблема, он же, по большей части, записывается один раз, и далее только читается. С другой стороны, ещё нет диска SSD, который просуществовал бы десять лет. К тому же, современная операционная система записывает данные во время чтения тоже, как минимум обновляет дату прочтения, поэтому мы не знаем точно, сколько циклов перезаписи было, насколько устройство близко к концу своей жизни. Есть множество информации и исследований в интернете, какой срок жизни можно ожидать от диска SSD, но они относятся к конкретным моделям и каким-то методологиям тестирования, мы не можем знать, как поведёт себя конкретный диск с нашими данными.
SSD — перспективная технология. Из-за её скорости и надёжности, на неё переходят корпоративные базы данных, переносные компьютеры, именно такая память в планшетах и мобильных телефонах. Но все эти устройства рассчитаны на 3-5 лет постоянной работы, они не планируются как архивные устройства. Главный диск моего лэптопа, SSD, вышел из строя через 4 года работы, и его поменяли по гарантии.
На сегодняшний день мой выбор архивного устройства — внешний компактный жёсткий диск, с соблюдением всех мер осторожности ввиду его хрупкой механической натуры. Выбор, в основном, ввиду его цены. Время покажет, станут ли SSD дешевле, ведь как раз сейчас в мире кризис полупроводников. Заодно и узнаем с годами, какова их надёжность в смысле долговременного хранения информации.
А вот если выбирать между «крупным», настольным жёстким диском (типа «книжка») или «портативным», маленьким жёстким диском (типа «паспорт») — то я выбираю паспорт, хотя он и дороже раза в два, по сравнению с аналогичного объёма настольным диском. Почему? Во-первых, он занимает меньше места. Во-вторых, он не требует блока питания, который тоже может быть источником проблем: он может перегреться, задымиться, в нём может быть излом, который приведёт к сбою питания, который может испортить информацию. Практика показывает, что компактные диски надёжнее, их механика рассчитана, насколько можно, на «мобильное» использование. Компактный диск легче взять с собой в поездку.
Если для архива я выбираю жёсткие диски (хоть и компактные), то для резервной копии во время поездок у меня есть и внешний SSD. На него копируются отснятые кадры. На нём хранятся дополнительные данные, не нужные каждый день, например, программы, на случай если надо будет что-то переустановить, или копия какой-то части архива, которая может понадобиться в поездке.
Таким образом, даже в поездке, вне дома, все отснятые кадры у меня в трёх копиях: в компьютере, на внешнем отключённом SSD, и на внешнем жёстком диске. А после поездки, дома, всё будет просмотрено, прорежено, что-то будет удалено, а что-то — заархивировано, как уже говорилось, в трёх копиях и в облаке. И убрано с основного компьютера и его резервных копий.
NAS, RAID и другие
Поскольку все мы подключены к сети, а наши сети соединены в сеть сетей — интернет, сейчас очень популярны хранилища данных, напрямую подключённые к сети, так, что к ним можно обращаться с любого компьютера.
Из корпоративного мира в наш дом пришли устройства NAS — Network Attached Storage — подсоединённое к сети хранилище, и принцип RAID — Redundant Array of Inexpensive Disks — избыточный массив недорогих дисков.
Устройство NAS, или «сервер» NAS — это устройство с дисками, подключённое напрямую к сети, а не к компьютеру. На самом деле, это полноценный компьютер со своей операционной системой, просто подключаемся мы к нему через сеть.
RAID — это принципы, позволяющие с помощью дополнительных дисков повысить надёжность системы.
Вот пара примеров RAID:
- информация записывается на два диска одновременно, и тогда, если один из дисков сломается, а второй останется исправным, то данные не пострадают, испортившийся диск можно заменить новым и скопировать на него информацию с уцелевшего; при этом методе потребуется вдвое больше дисков, чем необходимый объём данных, например, два диска по 6 терабайт обеспечат надёжное хранение шести терабайт; это называется mirroring — «зазеркаливание», каждый диск из двух содержит абсолютно идентичную информацию;
- если есть три или более диска, то достаточно умное устройство может так распределить информацию по ним, что гарантирует восстановление информации при выходе из строя одного из трёх дисков, а объём записанной информации будет две трети от объёма всех дисков. При такой технологии три диска по шесть терабайт обеспечат надёжное хранение двенадцати терабайт информации, это даже выгоднее, чем при зазеркаливании.
Если в NAS есть возможность включить какой-то из вариантов RAID-а, то у нас есть выбор, воспользоваться ей, или нет.
Это, конечно, замечательные устройства, и у меня самого дома есть сервер Synology, и он мне очень нравится. Я только хочу заметить следующее:
Надо очень хорошо понимать, от чего эти устройства нас защищают, а от чего — не защищают. Вернитесь к списку в начале статьи, от чего мы защищаемся? От сбоя оборудования RAID нас спасает, но только от сбоя одного из дисков. А вот от программной ошибки, от человеческой ошибки — нет. Вы можете вложить уйму денег в сверхнадёжный массив с четырьмя дисками, но одно неверное нажатие Delete или несвоевременное нажатие Save — и весь ваш массив надёжно сохранит неверную информацию. Иными словами, как и диск компьютера, и сам компьютер, он не должен быть Вашей единственной копией данных.
Главное назначение RAID-ов — обеспечивать бесперебойную работу, доступность сервера, даже если испортится один из дисков. В случае домашнего архива это — не первая цель. Нет необходимости, чтобы круглосуточно бесперебойно работал компьютер, на котором я работаю с документами, фотографиями или архивом. Такая необходимость есть для веб-сайта, почтового сервера, блога — таких служб, к которым могут в любое время обратиться из интернета, и которые должны быть всегда доступны. В «умных домах», конечно же, сервер должен работать бесперебойно, чтобы открывать двери, включать свет, сливать информацию с камер наблюдения, и прочее. Для таких служб, конечно же, нужна «высокая доступность» (High Availability), и RAID там, возможно, оправдан. Но тогда он, по определению, является первой копией, и, по описанным нами выше соображениям, сам по себе нуждается в резервной копии. (Кто там говорил о моей паранойе?) А если мы храним на таком сервере лишь одну из трёх копий архива, или одну из двух резервных копий рабочего диска, то тогда, при наличии других, отсоединённых копий, RAID большого смысла не имеет. Хороший вместительный диск на 12 терабайт сегодня может стоить около 300 долларов, а на 18 терабайт — даже 600, нет смысла дублировать его, на эти деньги можно приобрести объектив, другое оборудование или ещё внешних архивных дисков.
Облачные службы
Облачные службы хранения — главный хит сезона, весь мир переходит в «облако», хранит там свои файлы, и даже арендует там вычислительную мощность. Выше мы сказали, что облако — хорошее место для одной из резервных копий наших данных и для одной из копий архива.
Я не буду давать советов про конкретные службы, опять же, потому что цены и условия постоянно меняются. DropBox, Box, Microsoft OneDrive, Amazon Drive, Google Drive, Apple iCloud — все предлагают более-менее сходные услуги, а цены могут существенно различаться. Нужно проводить конкретные сравнения под конкретные нужды, потому что могут быть особенности. Например, Амазон когда-то предлагал неограниченное хранилище за фиксированную плату, потом они такой план отменили, но сейчас поддерживают неограниченное хранилище для фотографий в составе Amazon Prime. Для меня это идеальный вариант, потому что из 21 терабайта моего архива, более 20 — это фотографии, и фиксированная сумма в год на сегодняшний день гораздо выгоднее, чем любая опция с оплатой каждого терабайта. Надо внимательно читать условия. BackBlaze, например, предлагает неограниченное в объёме хранилище, но всё это хранилище должно располагаться на одном диске.
Все или почти все клиентские программы облачных служб предоставляют возможности:
для резервного копирования:
- автоматическое резервное копирование («бэкап»);
- синхронизированные папки — папки, которые автоматически отображаются на локальный диск компьютера и все изменения в них синхронизируются с облаком. С такими папками можно работать с нескольких компьютеров;
- автоматическую загрузку фотографий с мобильных телефонов.
для архивации данных:
- «ручной» загрузки файлов в сервис — подходит для данных, которые мы вручную убираем с рабочего диска в архив.
В Amazon S3 есть интересные возможности баланса между доступностью данных и ценой хранения. Для архивной копии, вероятность, что мы вообще когда-либо будем считывать данные, достаточно мала. Если в случае необходимости можно подождать день-два с загрузкой данных, то «ледник» Amazon S3 Glacier будет значительно дешевле, чем если данные должны быть доступны каждую минуту.
В принципе, к облачному хранилищу надо относиться, как к одному из архивных дисков. Надо хорошо представлять себе, что, как и с обычным диском, с ним может случиться сбой, и ответственность поставщика услуг ограничена контрактом. Однажды JustCloud потерял половину данных, которых я у них хранил. На тот момент это было около четырёх терабайт. И хотя они очень извинялись, и вернули деньги за последний год, найти и вернуть данные они не смогли. И это может случиться, никто не застрахован. Вернут они деньги или не вернут — зависит от контракта, но нам нужны наши данные, и в этом смысле, облачная служба — всего лишь одна из копий, которая может «сломаться».
Надо также учитывать скорость загрузки в облако. Возьмите размер архива, разделите его на пропускную способность вашего исходящего соединения (upload). В домашних подключениях часто исходящее соединение медленнее входящего. Посчитайте, сколько времени займёт загрузить весь архив в облако, и сколько времени будет занимать дозагрузка каждой новой порции архива. Надо продумать, как можно это автоматизировать. Если это стационарный компьютер, можно создать запланированную задачу на ночь. А если компьютер портативный, и мы с ним ходим на работу или ездим в поездки? Тогда можно попробовать поручить загрузку в облако серверу, который остаётся дома, в домашней сети. Уже упомянутый выше сервер Synology содержит некоторые клиенты популярных облачных служб, которые могут загружать данные в облако. Но тогда эти данные должны попасть с нашего лэптопа на сам сервер Synology, что, опять же, требует автоматизации.
Ещё одна особенность облачного хранилища — пока что нет возможности легко сравнить локальные данные с облаком. Чтобы хоть что-то сделать с «облачными» данными, в том числе и просто сравнить их с локальной копией, надо в первую очередь «сгрузить» их к себе из облака*. А если объём архива, который мы храним в облаке, больше диска нашего компьютера, значит, нужен пустой внешний носитель, на который можно будет сгрузить данные, плюс нужно, опять же, время.
*Тут, конечно, можно возразить, что «что-то» с файлами можно сделать, не сгружая. Например, (почти) во всех облачных службах фотографии и видео можно начерно просмотреть через браузер, в Google Drive некоторые документы можно открыть через соответствующие веб-приложения вроде Google Docs, в облаке iCloud от Apple тоже можно редактировать документы. В облаке Adobe можно просматривать и редактировать файлы в формате Photoshop. Поставщики облачных услуг хотят приучить нас к «жизни в облаке», причём каждый из них стремится привязать нас именно к своему облаку. О «жизни в облаке» я напишу отдельную статью, там есть множество аспектов. А про возможности удалённой работы с файлами в облаке только отмечу, что эти возможности пока что очень разрознены, и далеко не с каждым файлом можно что-то удалённо сделать. В контексте нашего обсуждения: для бинарного сравнения архива с его облачной копией, сегодня, во всех крупных облачных службах, копию придётся сгрузить, а потом уже сравнивать.
Так же, как и с локальным диском, нам надо учитывать, что, возможно, нам когда-нибудь придётся из одной такой службы мигрировать в другую. И что сгрузить данные из облака займёт уйму времени, особенно, если мы их туда складывали годами. Если нам разонравилась какая-то служба, и мы хотим перейти на другую, мы не хотим сгружать всю информацию из облака, мы хотим стереть её там, а в новую службу загрузить из дома.
Поэтому скажу то, что уже сказал выше неоднократно: «облако» должно быть только одной из копий хранилища, не единственной и не главной.
Каталогизация. Как мы помним, что где?
Тома и метки томов
Мы переносим информацию в архив частями. Идея в том, что информация в архиве не должна меняться, поэтому переносим в архив то, что уже закончено, сделано, и не будет меняться. Если будет новая версия, новый вариант обработки какой-то фотографии — он попадёт в новую порцию архива.
Поэтому архив будет состоять из множества «томов». Каждая новая порция данных, убывающая с основного компьютера в архив, должна быть каталогизирована. Для этого можно воспользоваться электронной таблицей, например, Excel, Google Sheets, Apple Numbers, или какой-нибудь базой данных, например Access. Надо будет записать, где, на каком носителе находятся данные, и кратко описать, что в этом «томе»: документы, фотографии, обработанные работы, с какого и по какое время создания. Цель этой таблицы-каталога в том, чтобы знать, где искать данные, поэтому каждому тому должна соответствовать запись, позволяющая легко найти нужный том и «не лезть» в остальные. Название, или «метка» тома, могут содержать ключевое слово и даты, или только даты, или просто последовательный номер. Например:
Таблица: разные варианты меток томов и каталога
Вариант А. Текстовая метка тома
| Метка тома | Содержание | Носитель |
|---|---|---|
| Фотографии 2019-2020 (исходные файлы) | Поездка в США | Внешний диск №4 |
| Фотографии 2019-2020 (обработанные) | Проект «хороший отпуск» | Внешний диск №4 |
Вариант Б. Метка тома в виде даты или периода
| Метка тома | Содержание | Носитель |
|---|---|---|
| 2018.06-2019.03 | фотографии | Внешний диск №4 |
| 2017.11-2018.05 | фотографии | Внешний диск №4 |
| 2019.01-2019.12 | Документы | Внешний диск №4 |
Вариант В. Метка тома в виде номера
| Метка тома | Содержание | Носитель |
|---|---|---|
| 135 | фотографии июль 2019-сентябрь 2019, Прованс | Внешний диск №4 |
| 136 | фотографии сентябрь 2019-октябрь 2019, США | Внешний диск №4 |
| 137 | выставка в доме культуры | Внешний диск №4 |
Каталог работ
Фотография, рисунок, статья, книга, документ, проект детали или изделия — это всё примеры файла или папки, над которым мы долго работаем. Он находится на нашем основном диске и его резервных копиях. Когда-нибудь работа над ним будет закончена, и этот документ, наша «работа», «уйдёт в архив».
Она попадёт на один из архивных томов. Через какое-то время мы захотим её найти. Посмотрим на примеры каталога выше. Допустим, что работа, о которой речь — это фотография, сделанная в той поездке в США в октябре 2019. Когда она мне понадобится, я знаю, на каком томе архива её искать: на томе 136, который на внешнем диске № 4. А вот если я отредактирую эту работу потом ещё раз, когда том 136 уже записан?
Как мы уже говорили выше, архив не предполагает изменений, только дополнения. Технически, жёсткий диск позволяет дописать файл в папку, то есть новый файл можно добавить в том 136 на внешнем диске № 4. Категорически не рекомендую это делать. Во-первых, надо будет обновить все три копии архива и ту копию, что в другом месте или в облаке, и сделать это очень аккуратно, чтобы у всех файлов совпали даты изменения. Во-вторых, если сделан каталог этого диска с помощью windiff или другой программы, то он уже не будет соответствовать действительности, и его надо будет тоже переделать. В-третьих, через годы будет вызывать вопрос, почему у файла, относящегося к определённому периоду, другая дата изменения, причём, возможно, дата изменения папки тоже будет другой. В-четвёртых, есть риск повредить что-то рядом (я уже говорил о паранойе?). И, вообще, это не подходит как методология на долгое время, потому что оригинал файла может быть на старом, не перезаписываемом носителе, на диске CD, DVD или ленте. И это не годится для будущего, когда внешний диск, возможно, уже будет заполнен под завязку. Нет, нет и нет — ни в коем случае не изменяем готовые архивные тома. Что сделано в 2021-м, должно быть в архиве 2021-го, а не 2019-го.
Кроме всего прочего, я могу помнить, что работа была отредактирована для какого-то события (фотография — для выставки или публикации, статья — для симпозиума), и поэтому хочу искать работу в томе, относящемся ко времени симпозиума, а не в том, который был во время создания оригинальной работы.
Правильное решение, как это ни звучит нудно и бюрократически — вести список своих работ. Большой проект, в который вложены усилия, требует разумных усилий по его сохранению. Нет выбора, придётся завести ещё одну таблицу.
Таблица: Пример каталога работ
| Работа | Описание | Детали | Ключевые слова | Вариант | Дата создания | Том архива |
|---|---|---|---|---|---|---|
| Пейзаж в Центральном Парке | Вид на небоскрёбы Манхэттена из центрального парка | Вид на юг с края озера | Центральный Парк, Нью-Йорк, Манхэттен, 2019, октябрь, осень, небоскрёбы, зелень | «канонический», обработано по возвращении | Ноябрь 2019 | 136 |
| Для книги "хороший отпуск" (кадрирование, разрешение) | Январь 2020 | 141 | ||||
| Для выставки "Новый Город" (профиль принтера, цвета) | Сентябрь 2020 | 153 |
Как называть работу, какие должны быть детали и ключевые слова — тема для отдельной статьи. Это зависит от автора, ведь ему искать. Важен принцип: у нас есть электронная таблица или простейшая база данных, которая позволит нам найти нужный вариант работы и понять, на каком томе архива он находится. Ключевые слова, детали, описание — всё это поможет нам найти работу, о которой речь, тот её вариант, который нужен сейчас для сегодняшней цели. И который, возможно, станет новым вариантом работы, и ляжет потом в новый том архива.
Конвертация архива и каталога
Надо иметь чёткое представление, что то, в каком виде мы храним данные сейчас, с годами обязательно изменится. Мы говорили об этом выше. Только на моём веку прошло около дюжины видов носителей: дискеты 5.25″, 3.5", зип-драйвы на 100МБ и джаз-драйвы на 1ГБ, ленты QIC («стримеры») на 200МБ, ленты DAT на 1, 4 и 24ГБ, диски CDR (700МБ), DVDR (4.3 и 4.7ГБ), внешние диски настольные и компактные, и это не считая девятидорожечной ленты «больших» компьютеров и дискет 8 дюймов.
Когда-нибудь обязательно встанет вопрос, что существующий архив надо перенести на новый носитель. В 1994 году у всех компьютеров были дисководы, а CD — далеко не у всех. В 2007 году у всех компьютеров были DVD, которые, к счастью, читали и CD. Ну, и так далее. Уже в 2000 году стало понятно, что архивные дискеты надо переписать на CD и DVD.
В 2010-м году я начал переписывать 910 своих CD и DVD, располагавшиеся в четырёх толстых папках по 280 штук, на внешние диски USB, тогда 1ТБ, а теперь по 5ТБ. Теперь мой архив располагается на нескольких внешних жёстких дисках, некоторые из них — по одному терабайту, некоторые — по два, а некоторые — по четыре. Я хорошо осознаю, что когда-нибудь мне придётся переписать те диски в 1ТБ и 2ТБ на какие-то новые, по 4ТБ, по 8ТБ или какие они там будут, когда это станет срочным.
Значит, система каталогов должна подразумевать расширение и изменение способа хранения. Если где-то в моём каталоге записано, что файл фотографии 2006-го года находится на CD номер 345, то, значит, где-то придётся приписать, что диск 345 сейчас лежит в виде папки с именем 345 на внешнем носителе номер три, как когда-то было написано, что диск 345 лежит в папке номер три на полке номер два. Это звучит сумасшествием, но это правда жизни. Ведение каталога требует продумывания, внутренней дисциплины и постоянных вложений труда. Понятно, что и формат каталога поменяется со временем.
Я для себя решил эту проблему так: хотя «дисков» давно нет, ни CD, ни DVD, я продолжаю записывать информацию нумерованными порциями. Порции уже не обязаны быть ровно по 4.7ГБ, как было для DVD, а могут быть произвольного размера. Но я продолжаю вести список «дисков», то есть, фактически, пронумерованных «порций» архива. Зато, когда надо соединить два терабайтных носителя, переписать их на один четырёхтерабайтный, мне достаточно пройтись по каталогу этих «порций» (бывших DVD) и записать, на каком носителе они находятся теперь. Например, «диски» с 345 по 810 сейчас переехали на четырёхтерабайтный носитель номер 9.
Выводы
Запишем на память:
- Всегда делаем резервную копию главного набора данных своего рабочего компьютера, желательно две, на другой диск, в локальную сеть и/или в облако;
- Архивируем свои работы, убираем их с компьютера, подверженного старению, сбоям, вирусам и атакам;
- Держим три копии архива, физически отключённые от компьютера + хотя бы одну из них в «облаке» или в другом месте;
- Никогда не присоединяем к компьютеру более двух копий архива сразу;
- Тщательно и дисциплинированно ведём каталог своих дисков;
- Ведём учёт своих работ и их «версий», в каком году они обрабатывались, переобрабатывались, печатались, на каком оборудовании, где лежат сейчас.
Это только краткие выдержки из огромной массы материала, который я готовлю для книги. В этой выдержке я не говорил о проблемах устаревания программных средств и форматов файлов, виртуализации, именования файлов, об учёте уникальности и многих, многих других вопросах, связанных с тем, как не потерять данные.
Мне бы очень хотелось знать ваши отзывы об этом материале, был ли он полезен, навёл ли на интересные мысли. Также интересно, с какими ещё вы сталкивались проблемами при хранении данных, о чём ещё стоит рассказать, какие трудности возникали. Пишите комментарии и/или пишите автору лично, я всё внимательно прочту.
Надёжного вам хранения данных!